Amazon Simple Storage Service (S3) is the biggest and most optimized object storage service to build a data lake with structured and unstructured data and the storage service of choice. With Amazon S3, it is possible to build and scale a data lake of any size cost-effectively in a secure environment where data protection is in the range of 99.999999999 (11 9s) of durability.
But before going into building S3 data lake it is necessary to know more about data lake, the need for it and the essential elements of data lake and analytics solution.
What is a data lake?
A data lake is a centralized storehouse that allows you to store data – structured or unstructured – of any scale. The advantage here is that data can be stored as it is, without having to format or structure it. The data can then be used to run a wide range of analytics including big data processing, dashboards and visualizations, machine learning and real-time analytics based on which businesses can take better informed and accurate decisions. For more information and knowledge now get to start from online Amazon certification courses by using Udemy coupon with you maximum saving offers.

The need for data lake
In the current competitive business environment organizations that can derive and generate the maximum business value from their data will inch ahead in the race for the top. Companies that implement Data Lake outperform others in business growth and development because they can deploy new and innovative types of analytics. Machine learning is one of them that can be used over new sources like social media, data from click streams, log files and Internet-connected devices stored in the data lake.
Benefits here are the ability to identify and act upon opportunities faster for business growth by attracting and retaining customers, proactively maintaining devices, making informed and analytical decisions and boosting productivity. Aws course available for improve your knowledge.

The key attributes of a data lake
When organizations build data lakes and an analytics platform, it is essential to know their key attributes and how they can be used for a stronger business foundation.
- Secure storage and data catalog – Data lakes allow you to store both relational and non-relational data. The former includes all data from the line of business and operational databases while mobile apps, IoT and social media fall in the latter category. You can understand better what data is in the lake by cataloging, indexing and crawling through the data.
- Movement of data – You can import any amount of data that is available in real-time with data lakes. This data is collected from multiple sources and shifted to the data lake in the original format. Through this process, therefore, you can scale to data regardless of the size and save time in schema, transformations, and defining data structures.
- Machine Learning – With data lakes, you can generate various types of insights. You can report on historical data, use machine learning where models are structured to forecast possible outcomes and recommend a range of prescribed options to achieve optimized results.
- Analytics – Data scientists, data developers, business analysts, and other key personnel in your organization can access data with tools and frameworks of their choice. It includes commercial offerings from data warehouse and business intelligence vendors as well as open-source frameworks like Apache Spark and Presto. Data lakes allow you to run analytics without having to move data to a separate analytics system.
The significance of a data lake
Data Lake can harness more data from many sources and can significantly add value to your organization through better and faster decision making by empowering users to collaborate and analyze data in different ways. Some of the benefits are –
- Improved R&D Innovation choices – A data lake will enable your R&D teams to refine assumptions, test their hypothesis, and access results. This covers various areas – doing genomic research for more effective medication, understanding the attributes that customers will be willing to pay for and choosing the right materials in product design for faster performance.
- Improved customer interactions – A data lake can combine data of customers from a CRM platform with social media analytics including buying history and incident tickets. You can thus know the most profitable customer group, the response if any from customer churn and which promotions or rewards will increase customer loyalty.
- Increased operational efficiencies – The Internet of Things (IoT) can collect data in several ways on processes like manufacturing, with real-time data originating from Internet-connected devices. A data lake makes it easy to store massive amounts of data, run analytics on machine-generated IoT data to lower operational costs, and increase data quality.
Now that the intricacies of Data Lake per se have been seen in detail the many intricacies of the Amazon S3 data lake will now be analyzed.
What is Amazon S3 as a Data Lake Storage Platform?
The Amazon Simple Storage Service – S3 – data lake solution uses Amazon S3 data lake as its main storage platform. The virtual unlimited scalability of this platform provides an optimal foundation for a data lake. You can easily and seamlessly increase storage capacities from gigabytes to petabytes of content with 99.999999999 (11 9s) durability, paying only for the quantum used. Other outstanding features include scalable performance, native encryption, and access control capabilities and easy-to-use features. Most importantly, Amazon S3 can quickly integrate with a broad portfolio of AWS and other third-party ISV data processing tools.
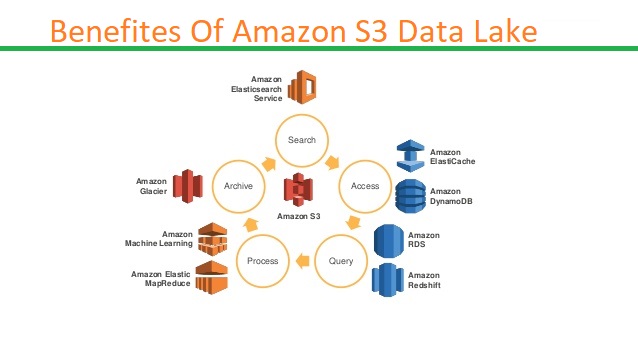
Benefits of Amazon S3 Data Lake
There are several benefits of Amazon S3 data lake
- With a data lake built on Amazon S3, native AWS services can be used to run big data analytics, machine learning (ML), Artificial Intelligence (AI), high-performance computing (HPC), and media data processing applications. All these provide valuable insights from unstructured data sets.
- With Amazon FSx for Lustre, you can process large media workloads directly from the data lake and launch file systems for HPC and ML applications.
- Have the flexibility to make use of your preferred analytics, AI, ML, and HPC applications from the Amazon Partner Network (APN).
- Amazon S3 supports a wide range of features. Hence storage administrators, data scientists, and IT managers have the authority to enforce access policies, manage objects at scale and audit activities across their S3 data lakes.
Why use Amazon S3 to build a data lake
Data safety and data durability should be your top priority as a business owner. With 11 9s data durability on Amazon S3 data lake, if you store 10,000,000 objects in Amazon S3, the probability of losing a single one is one in 10,000 years! All uploaded objects on S3 across multiple systems have copies automatically uploaded and stored, thereby protecting against failures, errors, and threats.
Other critical reasons to use Amazon S3 to build a data lake are –
- Protection of data through an infrastructure that is suitable for the most data-sensitive organizations
- Elaborate resource procurement cycles are not required to quickly scale up storage capacity
- S3 data lake insulates against the failure of an entire AWS Availability Zone since it automatically stores copies across a minimum of three Availability Zones (AZs). AZs are separated by several miles to provide fault tolerance.
- Use AWS native services for analytics like HPS, ML, AI, and media data processing to run applications on a data lake
- Offers a wide range of data management features with broad flexibility to operate at an object level. This helps to manage at scale, configure access, optimize cost efficiencies, and audit data across an S3 data lake.
Ready to get started on Amazon S3? Sign up for an AWSC account, start using Amazon S3, and deploy a data lake on AWS.

Digital Web Services (DWS) is a leading IT company specializing in Software Development, Web Application Development, Website Designing, and Digital Marketing. Here are providing all kinds of services and solutions for the digital transformation of any business and website.








